컴퓨터 구조 및 설계 4장 연습 문제 풀이
| * 문제 풀이에 오류 또는 계산 실수가 있을 수 있습니다. * 문제는 컴퓨터 구조 및 설계 5판 기준입니다. |
| [4.3] 프로세서 설계자가 프로세서 데이터패스의 개선을 고려할 때, 최종 결정은 가격대 성능비에 따라 정해지는 것이 보통이다. 그림 4.2의 데이터 패스에서 시작한다. I-Mem, Add, Mux, ALU, Regs, D-Mem, Control 블록의 지연 시간은 ALU에 곱셈기를 추가하는 문제를 생각해보자. 곱셈기가 추가되면 ALU의 지연이 300ps 늘어나고, 비용이 600 추가되는 대신, 명령어의 실행이 5%정도 줄어드는 효과가 있다. |
|
4.3.1) 이 같은 개선이 이루어졌을 때와 이루어지지 않았을 때의 클럭 사이클 시간은 얼마인가? |
|
A : 클럭 사이클 시간은 가장 시간이 오래 걸리는 경로를 통해 실행 했을 때 알 수 있다. 이때 가장 많은 구간을 거치는 명령어는 lw,sw 같은 적재,저장 명령어이므로, 이를 가정하고 경로를 보면 I-Mem -> Regs -> Mux -> ALU -> D-Mem -> Mux 이므로, 이것을 이용해 계산하면 개선 전 - 400 + 200 + 30 + 120 + 350 + 30 = 1130ps 개선 후 - 1130 + 300 = 1430ps |
|
4.3.2) 이 같은 개선이 이루어졌을 때 얻게 되는 속도 향상은 얼마인가? |
|
A : CPU 실행시간 = IC*CPI*클럭사이클시간 공식을 사용한다. 개선 전 - IC*CPI*1130ps 개선 후 - IC*(0.95)*CPI*1430ps (개선 전)/(개선 후)로 전, 후를 비교하면 1130/(0.95*1430) = 약 0.83 속도는 0.83배로 더 느려졌다. |
|
4.3.3) 이 같은 개선이 이루어졌을 때와 그렇지 않을 때의 가격 대 성능비를 비교하라. |
|
A : 비용은 있는 부품의 가격을 모두 더해야하므로 그림4.2를 참고하면 I-Mem 1개, Regs 1개, Controls 1개, ALU 1개, D-Mem 1개, Add 2개, Mux 3개가 있으므로 개선 전 비용 : 1000 + 200 + 500 + 100 + 2000 + 2*30 + 3*10 = 3890 개선 후 비용 : 3890 + 600 = 4490 성능비 = 가격 대비 성능이므로, 가격 변화율 / 성능 변화율로 계산해보면 (4490/3890)/0.83 = 약 1.39, 가성비가 1.39배 더 나빠짐. (성능은 줄고, 가격은 올랐으므로) |
| [4.4] |
|
이 문제에서 프로페서의 데이터패스를 구현하는데 필요한 논리 블록들이 다음과 같은 지연시간을 갖는다고 가정한다. |
|
I-Mem |
Add |
Mux |
ALU |
Regs |
D-Mem |
Sign-Extend |
Shift-Left-2 |
|
200ps |
70ps |
20ps |
90ps |
90ps |
250ps |
15ps |
10ps |

|
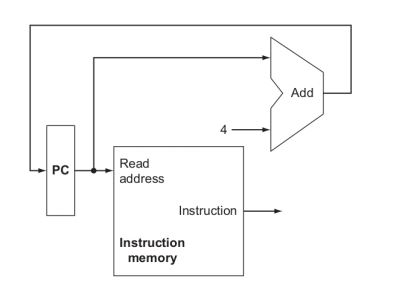
4.4.1) 프로세서가 할 일이 연속된 명령어들을 인출해 오는 것뿐이라면(그림 4.6) 사이클 시간은 얼마인가? |
|
A : I-Mem에서 명령어를 인출하는게 끝이므로 200ps. |
|
4.4.2) 데이터패스는 그림 4.11과 같은데, 명령어가 PC 상대 무조건 분기 명령어 하나밖에 없는 프로세서가 있다고 하자. 아 데이터패스의 사이클 시간은 얼마인가? |
|
A : 무조건 분기 명령어밖에 없다고 했으므로, I-Mem에서 명령어를 가져와 Sign-Extend와 Shift-Left-2를 통해 offset값을 가져오고, Add로 새로운 PC값을 계산한 다음 이 과정 동안 I-Mem, Sign-Extend, Shift-Left-2, Add, Mux가 사용된다. 따라서 200 + 15 + 10 + 70 + 20 = 315ps |
|
4.4.3) 위 4.4.2 문제를 그대로 하되, 이번에는 조건부 PC 상대 분기 명령어만 있는 것으로 가정하라. |
|
A : 위에 있는 무조건 분기 명령과 비슷한 경로를 가지지만, PCsrc 조건을 계산하기 위해서 Regs, Mux, ALU을 사용하는 경로가 200 + 90 + 20 + 90 + 20 = 420ps |
|
다음 세 문제는 데이터패스 구성 요소 중 Shift-left-2에 관한 것이다. |
|
4.4.4) 어떤 종류의 명령어가 이 자원을 필요로 하는가? |
|
A : 무조건 분기 명령어를 제외한 PC 상대 분기 명령어가 있다. |
|
4.4.5) 이 자원은 어떤 종류의 명령어의 경우에 최장 경로상에 있게 되는가? |
|
A: 그런 것이 없다. 위 2, 3번에서 Shift-left-2는 무조건 분기 명령어 하나 밖에 없는 프로세서에서 최장 경로 상에 있는데 실 |
|
4.4.6) beq와 add명령어만 지원한다고 가정했을 때, 이 자원의 지연시간이 변하면 어떤 영향을 미치는지 설명하라. 다른 자원의 지연시간은 변하지 않는다고 가정한다. |
|
A : 과정 중 Shift-left-2가 포함되지 않은 add의 경우 아무 영향이 없고, beq는 변화에 따라 총 사이클 시간이 변화한다.
|
| [4.7] |
|
연습문제에서는 명령어가 단일 사이클 데이터패스에서 어떻게 실행되는지 좀 더 구체적으로 살펴보려고 한다.이 문제들은 프로세서가 다음 명령어 워드를 인출하는 클럭 사이클에 관한 것이다. 101011/00011/00010/0000000000010100
데이터 메모리는 모두 0이며, 위 명령어 위드가 인출되는 사이클이 시작될 때 프로세서 레지스터의 값은 다음 표와 같다고 가정한다.
|
|
$0 |
$1 |
$2 |
$3 |
$4 |
$5 |
$6 |
$8 |
$12 |
$31 |
|
0 |
-1 |
2 |
-3 |
-4 |
10 |
6 |
8 |
2 |
-16 |
|
101011/00011/00010/0000000000010100 이 코드를 나눠보면 |
|
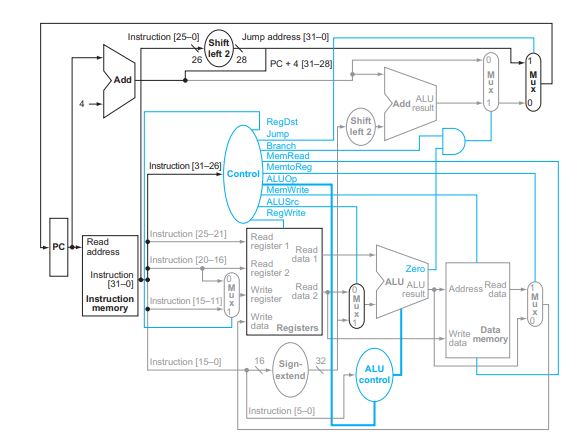
4.7.1) 그림 4.24에서 부호 확장 유닛의 출력과 왼쪽 상단의 점프 “Shift left 2" 유닛의 출력은 얼마인가? |
|
A : Shift left 2 유닛에 들어가는 값은 address값 앞에 16bit을 붙여 부호화했기 때문에 0000 0000 0000 0000 0000 0000 0001 0100 이며, 왼쪽으로 2번 Shift 되어 출력되면 0000 0000 0000 0000 0000 0000 0101 0000 이 된다. |
|
4.7.2) ALU 제어 유닛의 입력 값들은 얼마인가? |
|
A : sw의 ALUop 값은 00이며, 들어오는 ALU 제어 신호 값은 0010이다. |
|
4.7.3) 이 명령어가 실행된 후의 새로운 PC 주소는 얼마인가? 이 값이 결정되기 위해 거치는 경로를 강조하여 보아라. |
|
A : 점프 등의 분기 명령어가 없기 때문에, 명령 실행 후 PC값은 다음 주소를 나타내는 PC+4가 된다. 경로는 PC -> 상수 4가 있는 좌측 상단의 Add -> 우측 상단의 Mux -> PC 이다. |
|
4.7.4) 명령어가 실행되는 동안 각 Mux의 데이터 출력 값과 각 레지스터 값은 얼마인가? |
|
sw명령이라 Write Register 부분이 활성화 되지 않았기 때문에, Write Register 옆의 Mux의 출력 값은 없다. Data memory 오른쪽의 Mux 또한 Mux의 출력 값은 없다. 데이터를 저장할 주소를 찾기 위해서 주소를 rs에 추가한다. 따라서 ALU로 들어가는 Mux의 출력 값은 address 값이 된다. jump나 분기 명령어가 따로 없으므로 오른쪽 위의 2개의 Mux 값은 다음 주소 값인 PC+4가 된다. |
|
4.7.5) ALU와 두 덧셈기의 데이터 입력 값들은 얼마인가? |
|
A : 첫째 Add에 들어가는 값은 PC, 4 이다. 둘째 Add에 들어가는 값은 앞의 Add의 출력 값인 PC+4와, Shift-left-2의 출력 값인 0000 0000 0000 0000 0000 0000 ALU 입력 값은 첫째는 rs 값이다. rs = $3 = -3이므로, 첫째 값은 -3. 둘째 값은 앞에 나왔던 ALU앞의 Mux 출력 값인 address값. 즉, 0x00000014. |
|
4.7.6) 'Register' 유닛의 모든 입력 값들은 얼마인가? |
|
A : Write register 와 Write Data 값은 나오지 않았으며, Read Register 1 은 rs = 3 Read Register 2 는 rt = 2 Register Write 는 0이다. |
| [4.8] |
|
이 연습 문제에서는 파이프라이닝이 프로세서의 클럭 사이클 시간에 어떤 영향을 미치는지 알아본다. 데이터패스의 각 단계는 다음과 같은 지연 시간을 갖는다고 가정한다. |
|
IF |
ID |
EX |
MEM |
WB |
|
250ps |
350ps |
150ps |
300ps |
200ps |
|
또 이 프로세서의 실행 명령어 분포는 다음과 같다고 가정한다. |
|
alu |
beq |
lw |
sw |
|
45% |
20% |
20% |
15% |
|
4.8.1) 파이프라인 프로세서와 파이프라이닝 되지 않은 프로세서의 클럭 사이클 시간을 얼마인가? |
|
A : 파이프라인 프로세서에서 클럭 사이클 시간은 가장 시간이 많이 걸리는 단계의 지연 시간과 같다. 파이프라인 되지 않은 프로세서는 모든 단계의 지연 시간의 합이 클럭 사이클 시간이 된다. |
|
4.8.2) 파이프라인 프로세서와 파이프라이닝 되지 않은 프로세서에서 lw명령어의 전체 지연시간은 얼마인가? |
|
A : lw 명령어는 위 5단계를 모두 사용한다. 파이프라인 프로세서의 경우 350 * 5 = 1750ps, 파이프라인 되지 않은 프로세서는 위와 똑같이 1250ps 이다. |
|
48.3) 파이프라인 데이터패스의 한 단계를 지연시간이 절반인 단계 두 개로 나눌 수 있다면, 어떤 단계를 나누는 것이 좋을 것이며 이때 프로세서의 클럭 사이클 시간은 얼마가 되는가? |
|
A : 당연히 가장 많은 시간이 걸리는 단계인 ID를 쪼개는 것이 좋으며, ID를 쪼갤 경우 350/2 = 175로 바뀌므로 그 다음으로 시간이 많이 걸리는 MEM 단계의 300ps가 답이 된다. |
|
4.8.4) 지연이나 해저드가 없다고 가정하면 데이터 메모리의 이용률은 얼마인가? |
|
A : 데이터 메모리에 접속하는 명령어는 sw, lw 둘 뿐이므로 둘의 분포 값인 20%, 15%를 더해 35%가 된다. |
|
4.8.5) 지연이나 해저드가 없다고 가정하면 ‘Register' 유닛의 Write register 포트의 이용률은 얼마인가? |
|
A : Register Write 기능을 사용하는 명령어는 alu, lw 뿐이므로 각각 45%, 20%를 더해 총 65%가 된다. |
|
4.8.6) 단일 사이클 구조 대신에 다중 사이클 구조를 사용할 수 있다. 다중 사이클 구조에서 각 명령어의 실행은 여러 사이클이 걸리며 현재 명령어의 실행이 끝나야만 다음 명령어를 인출하게 된다. 이 같은 구조에서는 모든 명령어가 실제로 필요한 단계만 거친다. 단일 사이클 구조, 다중 사이클 구조, 파이프라인 구조의 클럭 사이클 시간과 실행시간을 비교하라. |
|
A : 다중 사이클 구조의 클럭 사이클 시간은 가장 시간이 많이 걸리는 과정의 지연 시간이므로 350ps. 단일, 파이프라인 구조의 실행시간 = 명령어의 수 * 사이클시간이다. 실행 시간의 경우, lw는 5단계를 모두 사용하고, 나머지 alu, beq, sw는 4단계만을 사용하므로 다중 사이클 구조 실행시간 = lw명령어 수 * 5 * 사이클시간 + 다른 명령어 수 * 4 * 사이클시간 명령어 수를 1로 가정하고 퍼센트에 따라 정하면 다중 사이클 구조 실행시간 = 0.2 * 5 * 사이클 시간 + 0.8 * 4 * 사이클 시간 따라서, 다중 사이클 구조 실행시간 = 4.2 * 사이클 시간. 파이프 사이클 시간과 비교 시 4.2배 더많은 시간이 걸림
|
| [4.9] |
|
이 연습문제에서는 4.5절에서 설명했던 다섯 단계 파이프라인 프로세서에서 데이터 종속성이 프로그램 실행에 어떤 영향을 미치는지 알아보기 위해 다음 명령어 시퀀스를 사용한다. or $1, $2, $3 or $2, $1, $4 or $1, $1, $2 각 경우 클럭 사이클 시간은 다음과 같다. |
|
전방 전달이 없는 경우 |
완전한 전방전달이 있는 경우 |
ALU-ALU 전방 전달만 있는 경우 |
|
250ps |
300ps |
290ps |
|
4.9.1) 종속성과 그 종류를 나타내라. |
|
A : |
|
4.9.2) 이 파이프라인 프로세서에 전방전달이 없다고 가정한다. 해저드를 모두 표시하고 nop명령어를 삽입하여 해저드를 제거하라. |
|
A : $1이 2,3째 줄의 $1에 종속성이 있으므로 1,2째줄 사이에 nop 2개, 2,3째줄 사이에 nop 1개가 필요하다. 2번째 줄의 $2이 3째 줄을 실행하는데 필요하여 종속성이 있으므로 2,3째줄 사이에 nop 1개가 더 필요하다. or $1, $2, $3 nop nop or $2, $1, $4 nop nop or $1, $1, $2 |
|
4.9.3) 완전한 전방전달이 있다고 가정한다. 해저드를 모두 표시하고 nop명령어를 삽입하여 해저드를 제거하라. |
|
A : 완전한 전방전달이 있다면 데이터 해저드가 일어나지 않으니 nop명령어를 삽입할 필요가 없다. |
|
4.9.4) 전방전달이 없을 때 이 명령어 시퀀스의 전체 실행시간은 얼마인가? 또 완전한 전방전달이 있을 경우에는 전체 실행시간이 얼마인가? 전방 전달이 없던 파이프라인 프로세서에 전방전달을 추가함으로써 얻게 되는 속도 향은 얼마인가? |
|
A : 실행시간 = 클럭사이클시간 * 사이클 수이다. 전방 전달이 없을 경우 클럭 사이클 시간은 250ps이고, 사이클 수는 전방 전달이 없을 시 1명령어 당 5사이클이 필요한데 각 명령어마다 EX과정이 끝나야 다음 값을 낼 수 있으므로 앞 명령어의 MEM과 다음 명령어의 IF과정이 겹치도록 배치하면 총 11사이클이 된다. 완전한 전방 전달이 있을 경우 클럭 사이클시간은 300ps이고, 해저드를 고려할 필요가 없으니 파이프라인 배치를 하여 총 7사이클이 나오도록 배치할 수 있다. 전방 전달 배치 전이 2100ps, 배치 후가 2750ps이므로 2750/2100 = 약 1.31 약 1.31배 빨라졌다. |
|
4.9.5) ALU-ALU 전방전달만 있다(MEM->EX단계로의 전방전달은 없다)고 가정하고, nop명령어를 삽입하여 해저드를 모두 없애라. |
|
A : ALU-ALU 전방전달을 사용 시 MEM->EM단계로의 전방 전달이 없으므로, 다음 명령어로 넘기는 것은 가능 하지만,첫째 명령어의 계산 값을 둘째 명령어로 넘기는 것은 불가능하다. or $1, $2, $3 or $2, $1, $4 nop or $1, $1, $2 |
|
4.9.6) ALU-ALU 전방전달만 있다면 이 명령어 시퀀스의 전체 실행시간은 얼마인가? 또 전방전달이 없는 파이프라인 프로세서에 비해 얼마만큼의 속도 향상이 있는가? |
|
A : 위에서 언급한 것처럼 1~2째줄 사이에는 전방전달이 일어나지 않으므로 첫째 명령어 EX이후에 IF를 배치해야한다. 2~3째줄 사이에는 정상적으로 전방전달이 작동하므로 파이프라인 배치가 되고, 따라서 우리는 총 9사이클이 된다는 것을 알 수 있다. 전체 실행시간 = 클럭사이클시간 * 사이클 수 이므로 ALU-ALU 전방 전달만 있는 경우 클럭사이클시간은 290ps, 사이클 수는 9이므로 290ps * 9 = 2610ps이다. 전방 전달이 없는 파이프라인 프로세서의 경우 4.9.4에서 구한 값인 2750ps이다. 따라서, 2750/2610 = 1.05 배 빨라졌다. |
| [4.12] |
|
이 연습문제는 파이프라인 프로세서에서 전방전달의 비용/복잡도/성능 간 타협 조건의 이해를 돕기 위해 만들어진 것이다. 그림 4.45의 파이프라인 데이터패스를 사용한다. 프로세서에서 실행되는 명령어 중에서 다음 비율만큼의 명령어는 RAW데이터 종속성을 갖는다. RAW 데이터 종속성의 종류는 결과값을 만들어 내는 단계(EX or MEM)와 그 결과를 사용하는 명령어[결과 값을 생성하는 명령어 바로 뒤의 명령어(1st) 또는 다음다음 명령어 (2nd) 또는 둘다]로 구분한다. 레지스터 쓰기는 클럭 사이클 전반부에서 이루어지며, 레지스터 읽기는 클럭의 후반부에서 이루어진다고 가정한다. 따라서 ‘EX to 3rd'나 ’MEM to 3rd' 종속성은 데이터 해저드를 발생시키지 않으므로 고려하지 않는다. 데이터 해저드가 없을 때 프로세서의 CPI는 1이라고 가정한다. |
|
Ex to 1st Only |
MEM to 1st Only |
EX to 2nd Only |
MEM to 2nd Only |
EX to 1st and MEM to 2nd |
Other RAW Dependences |
|
5% |
20% |
5% |
10% |
10% |
10% |
|
각 파이프라인 단계의 지연시간은 다음과 같다. EX 단계의 경우는 전방전달이 없는 경우와 두 종류의 전방전달 각 경우를 따로따로 표시하였다. |
|
IF |
ID |
EX (no FW) |
EX (full FW) |
EX(FW from EX/MEM only |
EX(FW from MEM/WB only) |
MEM |
WB |
|
150ps |
100ps |
120ps |
150ps |
140ps |
130ps |
120ps |
100ps |
|
4.12.1) 전방전달을 사용하지 않는다면 데이터 해저드에 의해 지연되는 사이클은 전체의 몇 %인가? |
|
A : 지연되는 횟수를 구해야한다. 지연된 명령어는 앞 명령어가 EX, MEM, WB 등의 단계를 끝내고 난 뒤 IF를 시작해야 하므로, Ex to 1st only종속이 일어날 때 2번의 stall이 일어나기 때문에 2개의 stall사이클을 가진다. 위 내용은 Ex to 1st and MEM to 2nd나 MEM to 1st에도 똑같이 적용된다. 따라서, Ex to 1st and MEM to 2nd 와 MEM to 1st Only는 각각 2개의 stall사이클을 가진다. Ex to 2nd 종속은 1개의 stall사이클을 가진다. 이를 이용해 지연되는 CPI를 구해보면 (0.05 + 0.2 + 0.1)*2 + (0.1 + 0.05)*1 = 0.85 데이터 해저드가 없을 때 CPI는 1이므로 새 CPI는 1+0.85 = 1.85가 된다. 따라서, 지연되는 사이클 비율은 0.85/1.85 = 약0.46, 46%이다. |
|
4.12.2) 만약 완전한 전방전달(전발전달을 할 수 있는 모든 결과 값을 전방전달)을 사용한다면 데이터 해저드에 의해 지연되는 사이클은 전체의 몇 %인가? |
|
A : 전방전달을 사용 할 경우, ~to 2nd 등의 다음다음 명령어로 인한 해저드가 모두 없어진다. 따라서 ~to 1st로 생기는 해저드만 고려하면 되는데, 이 중 첫 번째 명령어의 MEM의 결과를 다음 명령어의 ID로 보내야하는 것으로 발생하는 MEM to 1st로 인한 1번은 stall을 제외하고는 전방전달로 해저드가 해결된다. 따라서, 0.2 가 지연되는 CPI가 되고 총 CPI는 1+0.2 =1.2가 된다. 계산하면 0.2/1.2 = 0.17 = 17% |
|
4.12.3) 완전한 전방전달을 지원하기 위해서 필요한 3-입력 Mux가 없다고 가정하자. 그렇다면 EX/MEM 파이프라인 레지스터로부터만 전방전달(다음 사이클 전방전달) 하는 것이 더 좋을지 아니면 MEM/WB 파이프라인 레지스터로부터만 전방전달(두 사이클 전방전달)하는 것이 좋을지 결정해야 한다, 둘 중 어느 경우의 데이터 지연 사이클이 더 적은가? |
|
A : EX/MEM 레지스터로만 전방전달하는 경우, Ex to 1st에서는 해저드가 없지만, 나머지에서 전부 1번씩의 stall사이클이 발생한다. CPI를 구하면 0.2 + 0.05 + 0.1 + 0.1 = 0.45 MEM/WB 레지스터의 경우는 EX to 2nd에서는 stall이 일어나지 않지만 MEM to 1st에서 1번의 stall이 발생하며, Ex to 1st에서 첫째 줄 명령어의 MEM 단계 값을 다음 명령어로 전방전달 해야 하므로 1번의 stall사이클이 발생한다. CPI를 구하면 0.05 + 0.2 + 0.1 = 0.35 사이클 지연 시간이 적은 쪽은 MEM/WB 쪽이다. |
|
4.12.4) 주어진 해저드 발생 확률과 파이프라인 단계 지연시간의 경우, 전방전달이 없는 파이프라인에 완전 전방전달을 추가해서 얻을 수 있는 속도 향상은 얼마인가? |
|
위 문제에서 얻은 답을 대입한다. A : 전방전달이 없는 경우 전체 지연시간 - 1.85 완전전방전달 추가했을 때 전체 지연시간 - 1.2 시간이 줄어들수록 속도가 향상한 것이므로, 1.85/1.2 = 약1.54 |
|
4.12.5) 모든 데이터 해저드를 제거할 수 있는 시간여행 전방전달(time-traval forwarding)을 추가한다면 기본적인 전방전달 프로세서와 비교해서 얼마나 더 속도가 향상되겠는가? 시간여행 전방전달 회로는 아직은 존재하지 않는 상상 속의 장치이지만, 이것을 사용한 완전 전방전달 EX단계의 지연시간이 100ps 늘어난다고 가정하라. |
|
A : 클럭사이클 시간은 각 단계 중 가장 시간이 많이 소요되는 단계의 값으로 정해지므로 150ps. 기존 전방전달 프로세서의 경우 위 문제에서 구한것처럼 CPI = 1.2이며, 사이클시간은 150ps이다. 시간여행 전방전달을 추가한 경우 기본 CPI = 1이며, 사이클시간은 기존 150에 100이 더해진 250ps이다. 위 값으로 계산하면 1.2*150ps/1*250 = 약 0.72배로, 더 느려졌다. |
|
4.12.6) 연습문제 4.12.3을 반복하되, 이번에는 둘 중 어느 방법이 명령어 하나 당 소요 시간이 짧은지를 결졍하라. |
|
A : 명령어 당 소요 시간이므로 명령어 수는 1로 가정하고, CPI는 4.12.3에서 구한 값에 기본 CPI값 1을 더해서 사용한다. 양쪽 다 클럭사이클시간은 150ps다. 따라서, EX/MEM = 150ps * 1.45 = 217.5ps MEM/WB = 150ps * 1.35 = 202.5ps MEM/WB값이 더 작으므로, 답은 MEM/WB |
| [4.15] |
|
좋은 분기 예측기를 갖는 것이 얼마나 중요한지는 조건부 분기 명령어의 실행 빈도에 따라 달라진다. 분기 예측기의 정확도와 함께 분기 명령어 빈도는 틀린 예측으로 인한 시간 낭비의 양을 결정한다. 이 문제에서 동적 명령어 빈도는 아래와 같다고 가정한다. |
|
R 형식 |
BEQ |
J |
LW |
SW |
|
40% |
25% |
5% |
25% |
5% |
|
또한 분기 예측기의 정확도는 다음과 같다고 가정한다. |
|
항상 분기한다고 예측 |
항상 분기하지 않는다고 예측 |
2비트 |
|
45% |
55% |
85% |
|
4.15.1) 틀린 예측 때문에 발생하는 지연 사이클은 CPI값을 증가시킨다. 항상 분기한다고 예측하는 예측기에서 틀린 예측 때문에 추가되는 CPI는 얼마인가? 단, 분기는 EX단계에서 결정되며, 데이터 해저드도 없고, 지연 슬롯도 사용하지 않는다고 가정한다. |
|
A : 항상 분기한다고 예측하는 예측기에서 틀린 예측으로 인해서 3사이클의 stall이 추가된다. 따라서 계산하면 3 * (1-0.45) * 0.25 = 0.4125 |
|
4.15.2) 항상 분기하지 않는다고 예측하는 예측기에 대해 연습문제 4.15.1을 반복하라. |
|
A : 위와 똑같으나 항상 분기하지 않는다고 예측하는 것으로 바뀌어서 확률이 변화한다. 3 * (1-0.55) * 0.25 = 0.3375 |
|
4.15.3) 2비트 예측기에 대해 연습문제 4.15.1을 반복하라. |
|
A : 2비트에 있는 확률만 바꾸면 된다. 3 * (1-0.85) * 0.25 = 0.1125 |
|
4.15.4) 2비트 예측기를 사용할 때, 분기 명령어의 반을 ALU명령어로 대체할 수 있다면 속도 향상은 얼마인가? 올바르게 예측되는 명령어나 잘못 예측되는 명령어나 대체될 확률을 같다고 가정한다. |
|
A : 2비트 예측기에 대한 값은 4.15.3의 답 0.1125를 사용한다. ALU로 대체한 명령을 계산해보면, 분기 명령어의 절반은 ALU로 대체했으므로 절반은 분기에 의한 영향을 받지 않게 된다. 그럼 남아있는 나머지 절반의 분기 명령어로 인한 값만 구하면 되므로, 3 * (1-0.85) * 0.125 = 0.05625 위에서 구한 값은 CPI의 증가값이므로, 기본 CPI를 1이라 하고 계산해보면 (1+0.1125)/(1+0.05625) = 약 1.05 |
|
4.15.5) 2비트 예측기를 사용하고, 분기 명령어 하나를 ALU명령어 두 개로 대체할 수 있다면 분기 명령어의 반을 ALU 명령어 두 개로 대체할 경우 속도 향상은 얼마인가? 올바르게 예측되는 명령어나 잘못 예측되는 명령어나 대체될 확률은 같다고 가정한다. |
|
A : ALU 명령어 2개로 대체되는 것으로 바뀌었으므로, 기본 CPI 1에 바뀐 명령어 비율 만큼을 곱한 값이 추가로 늘어나게 된다. 4.15.4에서 구했던 절반만 있는 분기명령어의 CPI 증가값이 0.05625 였으므로, 둘을 더한 뒤 값을 구하면 0.125 + 0.05625 = 0.18125 기존 값보다 증가했으므로 느려졌으며, 비율을 구하면 1.1125/1.18125 = 0.94, 0.94배 더 느려졌다. |
|
4.15.6) 다른 것들에 비해서 좀 더 예측하기 쉬운 분기 명령어들이 있다. 실행되는 분기 명령어의 80%가 예측이 쉬운 순환문 분기 명령어라서 항상 정확하게 예측된다면, 나머지 20% 분기 명령어에 대한 2비트 예측기의 정확도는 얼마인가? |
|
A : 전체 분기 명령어 수를 1이라고 하자. 실행되는 분기 명령어의 80%가 순환문 분기 명령, 즉 beq와 같은 것이므로 남는 20%의 분기 명령어 중에서 순환문이 아닌 J를 찾아내는 확률이 정확도가 된다. 위 표에서 J의 분포는 5%므로, 남는 20%의 분기 명령 중에서 5%의 J를 찾아내는 것을 계산하면 (1*0.05)/(1*0.2) = 0.25. 즉, 25% |
'전공 > 컴퓨터구조' 카테고리의 다른 글
| 컴퓨터 구조 및 설계 2장 연습 문제 풀이 (0) | 2021.01.03 |
|---|---|
| 컴퓨터 구조 및 설계 1장 연습문제 풀이 (0) | 2021.01.02 |